A Multi-Granular Tabular Representation Learning Benchmark
TRL-Bench: Standardizing Cross-Paradigm Representation-Level Evaluation of Tabular Encoders
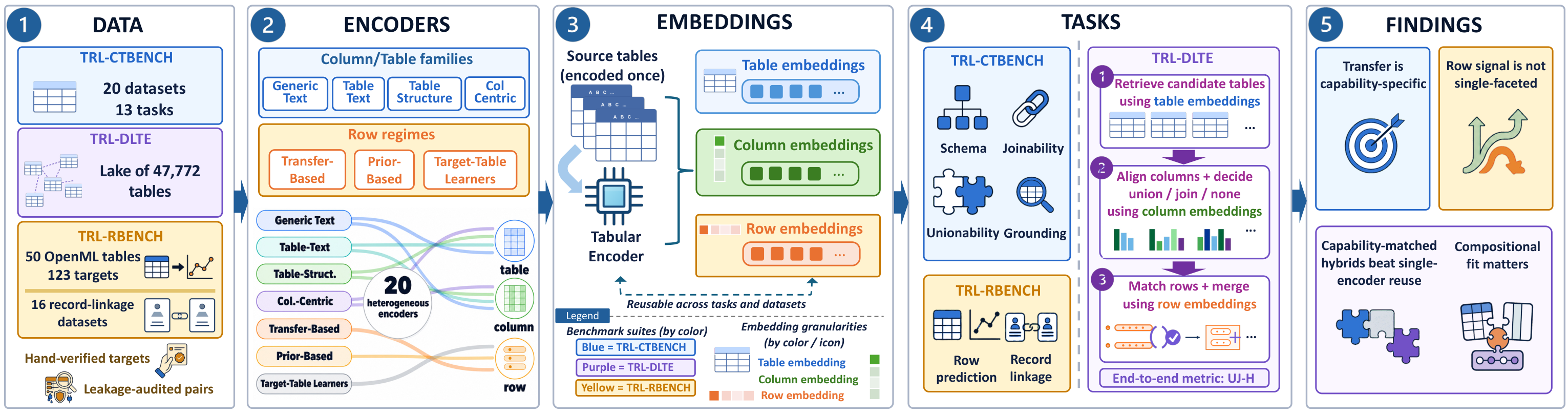
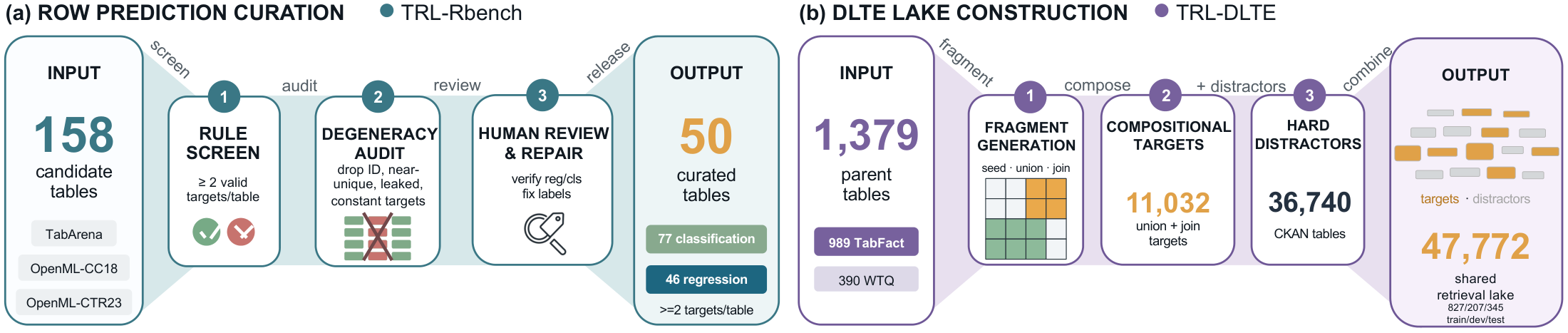
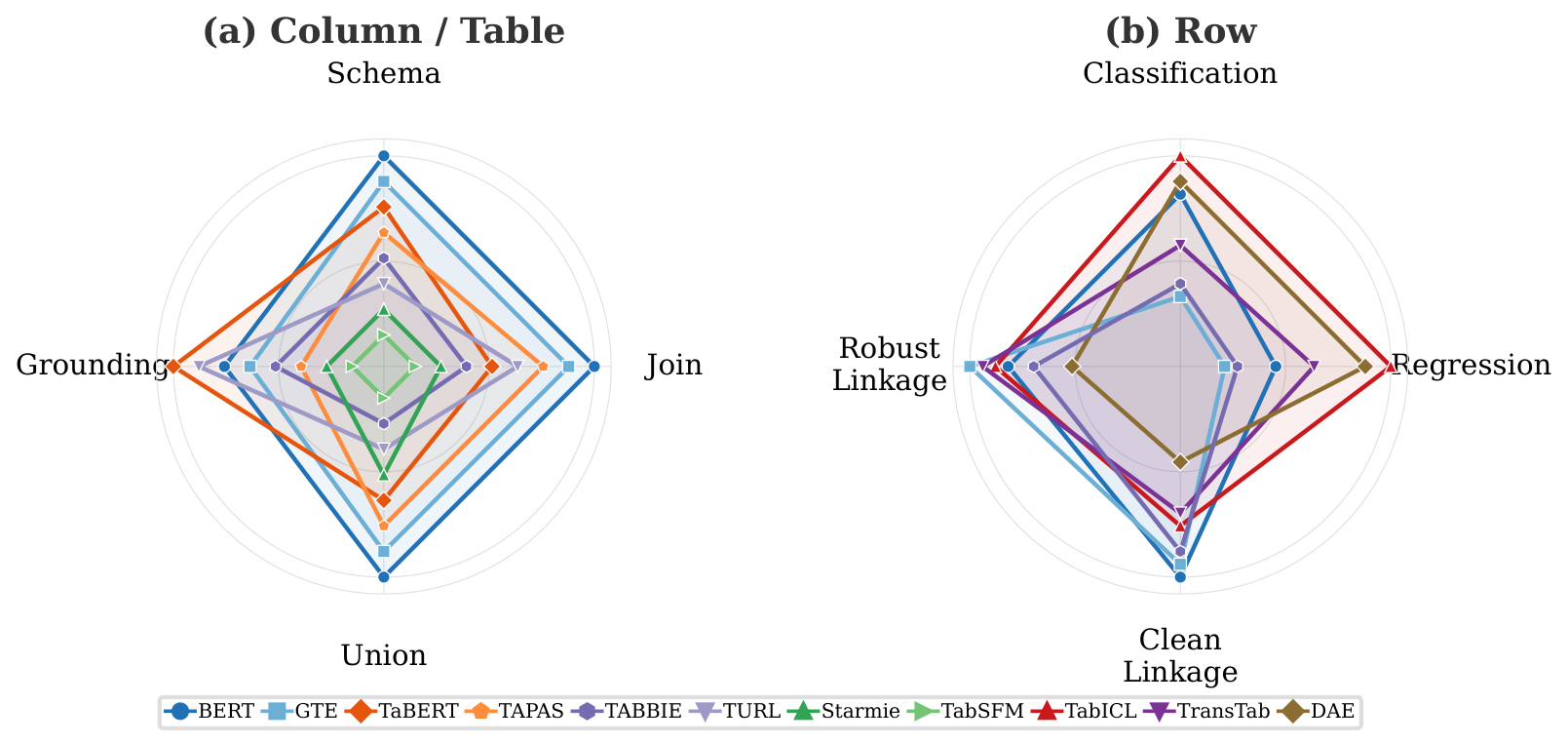
Tabular encoders span many paradigms — different inputs, training objectives, and output heads — so models are hard to compare even when they operate on similar tabular signals. TRL-Bench unifies them at the level of the representation: each model exports row-, column-, or table-embeddings through one shared wrapper, and lightweight shared heads probe them across 20 encoders, 16 tasks, and 87 datasets in three suites.
Datasets: TRL-CTbench · TRL-Rbench · TRL-DLTE